21:02 08-07-2002 Как увеличить производительность программы в nnnn раз, а потом ещё на 50%
Научи юзера быть терпеливым.
Постановка задачи
Есть искалка по pdf’ам. Она тормозит. Это неправильно. Она не должна тормозить. У заказчиков будет сто тысяч pdf’ок, и по ним нужно искать. За разумное время.
Исследование
У искалки внутри сначала выковыривание из pdf потока слов. Затем построение дерева слов (trie). В каждом листе дерева хранится список пар <индекс документа, номер страницы>. Клёво. Я об этом уже писал.
Эксперимент
Пишем на скорую руку тестовую аппликуху. Берём первую попавшуюся pdf’ку (Getting Started от Interbase).
Ладно, дело к ночи уже, уходим домой.
Утро
Всё ещё пишет?! ^F2.
Делаем заметку: алгоритм сохранения индекса неоптимальный.
Прикидываем, что дерево всё равно создаётся в памяти и для нормального поиска нужно загрузить индекс для всех документов. Вспоминаем, что их сто тысяч. . В память столько не влезет. Даже в виде trie.
. В память столько не влезет. Даже в виде trie.
Обдумываем план «Б» — запихать в базу данных табличку известных слов и известных документов, между ними повесить связь M:N с дополнительным атрибутом номер_страницы. Ставим маленький эксперимент на 20 слов и на том же 500-киловом Getting Started. Удовлетворяемся результатом.
Неделю работаем над другой задачей.
Понедельник
Другая задача кончилась. Возвращаемся со свежей головой к поиску.
Всё-таки, фигли ж он так долго индекс пишет?
F8. F8. F8.
Note: If the application goes idle, HandleMessage may take a long time to return. Therefore, do not call HandleMessage when waiting for something message-based while priority actions are also being processed. Instead, call ProcessMessages when processing more than just messages.
Аха. Тот самый случай. Типа, чтоб оно шевелилось, надо мышкой дёргать постоянно, а я домой ушёл, :редиска: такой.
Впрочем, проблему памяти это не решает. Чисто для себя, для спокойствия души — я разобрался. Но надо таки переезжать в базу. Пускай сервер думает, у него голова большая.
Выделяем в отдельную программу доставание слов из pdf. Они выходят из неё в одну строку, разделённые пробелами. Пишем ещё одну программу разделения их по одному в строке. Пишем третью программу для поднятия входа в uppercase. Так надо. Все заказчики любят case-insensitive сортировку и поиск.
Пишем ещё программу.
Регистрируем в базе все pdf’ки. Запускаем. Давим кнопку. По экрану пробегает полоска progress bar’а, свидетельствующая об успешном выполнении. Смотрим в базу. Что-то мало. Фиксим баг. Запускаем. Давим кнопку. Во. Нормально. Делаем ещё кнопку, которая проиндексирует нам все зарегистрированные документы, а не только выделенный. Вперёд. Мда. 300000 с лишним миллисекунд.
Спрашивается, куда уходит наше время=деньги?
Пишем класс, работающий как секундомер. .Start, .Stop, .Elapsed. Втыкаем их штук 10 на разные куски главного цикла, и ещё один на весь цикл. В конце — сбрасываем все показания в файл.
Запускаем. Поехали. Читаем файл. Суммируем всё. Не сходится сумма! Куда время теряется?
Достало. Обвешиваем весь цикл секундомерами, а не только чтение PDF, выполнение запросов к БД и прочие подозрительные на «тяжёлость» места. Запускаем.
Сходится! Ну, с точностью до 200ms. Ну да это фигня, не то что 15372ms.
Импортируем лог в Excel. Строим pie chart по показаниям секундомеров.
38% — обновление progress bar’а! Да ну его на… такой градусник.
Да ну его на… такой градусник.
Отрываем градусник. Во! Теперь 52% — загрузка PDF. Это сторонний компонент делает, я за него не отвечаю.
Вот они и 50%, обещанные в заголовке. Если время совершения работы уменьшается на 38%, то скорость, соответственно, увеличивается на 61%. 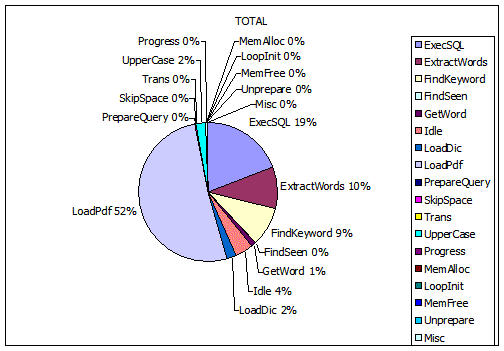
Постановка задачи
Есть искалка по pdf’ам. Она тормозит. Это неправильно. Она не должна тормозить. У заказчиков будет сто тысяч pdf’ок, и по ним нужно искать. За разумное время.
Исследование
У искалки внутри сначала выковыривание из pdf потока слов. Затем построение дерева слов (trie). В каждом листе дерева хранится список пар <индекс документа, номер страницы>. Клёво. Я об этом уже писал.
Эксперимент
Пишем на скорую руку тестовую аппликуху. Берём первую попавшуюся pdf’ку (Getting Started от Interbase).
tc := GetTickCount; t.AddWordStream(stm, t.AddDocument(filename)); t.WriteToStream(stmOut); Application.MessageBox(PChar(IntToStr(GetTickCount-tc)), '', 0)F2, F9. Висим? ^F2. F8, F8, F8, пока живём…
WriteToStream(stm);F8 — висим.
Ладно, дело к ночи уже, уходим домой.
Утро
Всё ещё пишет?! ^F2.
Делаем заметку: алгоритм сохранения индекса неоптимальный.
Прикидываем, что дерево всё равно создаётся в памяти и для нормального поиска нужно загрузить индекс для всех документов. Вспоминаем, что их сто тысяч.
Обдумываем план «Б» — запихать в базу данных табличку известных слов и известных документов, между ними повесить связь M:N с дополнительным атрибутом номер_страницы. Ставим маленький эксперимент на 20 слов и на том же 500-киловом Getting Started. Удовлетворяемся результатом.
Неделю работаем над другой задачей.
Понедельник
Другая задача кончилась. Возвращаемся со свежей головой к поиску.
Всё-таки, фигли ж он так долго индекс пишет?
F8. F8. F8.
t.WriteToStream(stm);F7.
for i := 0 to docList.Count - 1 do stream.WriteBuffer(docLen[i], sizeof(Word)); Application.HandleMessage;Почему я никогда не пишу в своём коде Application.HandleMessage?
Note: If the application goes idle, HandleMessage may take a long time to return. Therefore, do not call HandleMessage when waiting for something message-based while priority actions are also being processed. Instead, call ProcessMessages when processing more than just messages.
Аха. Тот самый случай. Типа, чтоб оно шевелилось, надо мышкой дёргать постоянно, а я домой ушёл, :редиска: такой.
{del 9014_C, 2002-07-08, Yuri V Khan
Application.HandleMessage;
enddel}
//ins 9014_C, 2002-07-08, Yuri V Khan
Application.ProcessMessages;
//endinsИ так по всему файлу, все вхождения. F2. F9. Ура, заработала! Сохраняет за секунды.Впрочем, проблему памяти это не решает. Чисто для себя, для спокойствия души — я разобрался. Но надо таки переезжать в базу. Пускай сервер думает, у него голова большая.
Выделяем в отдельную программу доставание слов из pdf. Они выходят из неё в одну строку, разделённые пробелами. Пишем ещё одну программу разделения их по одному в строке. Пишем третью программу для поднятия входа в uppercase. Так надо. Все заказчики любят case-insensitive сортировку и поиск.
$ dir /bs "%ProgramFiles%\InterBase\Doc\*.pdf">pdfs.lst $ pdf2wds @pdfs.lst $ cat *.txt|wordlist|sort|uc|uniq|egrep -e "^[A-Z]+$">words $ wc -l words 6956 wordsНе, нам столько не надо. Нам бы штук 300.
Пишем ещё программу.
$ rndlines 1 20 <words>wordsr
$ wc -l wordsr
330 wordsrВо, пойдёт.$ (set n=1000) & (for %%i in (@wordsr) do ^ (echo INSERT INTO ^ ARCHIVDICTIONARY (WORDID, KEYWORD) ^ VALUES (%n,'%i'); & ^ set n=%@inc[n]))|tee insert.sql>clip:Пускаем SQL Explorer, коннектимся к базе, Paste, Execute.
Регистрируем в базе все pdf’ки. Запускаем. Давим кнопку. По экрану пробегает полоска progress bar’а, свидетельствующая об успешном выполнении. Смотрим в базу. Что-то мало. Фиксим баг. Запускаем. Давим кнопку. Во. Нормально. Делаем ещё кнопку, которая проиндексирует нам все зарегистрированные документы, а не только выделенный. Вперёд. Мда. 300000 с лишним миллисекунд.
Спрашивается, куда уходит наше время=деньги?
Пишем класс, работающий как секундомер. .Start, .Stop, .Elapsed. Втыкаем их штук 10 на разные куски главного цикла, и ещё один на весь цикл. В конце — сбрасываем все показания в файл.
Запускаем. Поехали. Читаем файл. Суммируем всё. Не сходится сумма! Куда время теряется?
Достало. Обвешиваем весь цикл секундомерами, а не только чтение PDF, выполнение запросов к БД и прочие подозрительные на «тяжёлость» места. Запускаем.
Сходится! Ну, с точностью до 200ms. Ну да это фигня, не то что 15372ms.
Импортируем лог в Excel. Строим pie chart по показаниям секундомеров.
38% — обновление progress bar’а!
Отрываем градусник. Во! Теперь 52% — загрузка PDF. Это сторонний компонент делает, я за него не отвечаю.
Вот они и 50%, обещанные в заголовке. Если время совершения работы уменьшается на 38%, то скорость, соответственно, увеличивается на 61%.
Комментарии:
22:11 08-07-2002
Надо быть терпеливым... 
02:25 10-07-2002
progress bar - это плохо, в любом случае =))
А что такое "прогрес бар"? Это попытка увлечь пользователя в то время, как програма не справляется с поставленой задачей за разумное время! Вот, отсюда вывод - если пользователь понимает в этом контексте "прогрес бар" - то ну его к такойто матери это бар.
А что такое "прогрес бар"? Это попытка увлечь пользователя в то время, как програма не справляется с поставленой задачей за разумное время! Вот, отсюда вывод - если пользователь понимает в этом контексте "прогрес бар" - то ну его к такойто матери это бар.